Day 45 - 쿠버네티스 서비스
오늘 배운 내용
- 서비스 배포 방식
- 쿠버네티스 서비스
- 서비스의 엔드포인트
서비스 배포 방식
만약에 내가 nginx서버를 운영하다가 버전업을 했다면 서비스 버전 업데이트가 필요할것이다 이때 업데이트를 하는 방식에는 3가지 방법이 있다
1. 롤링 업데이트 ver2 서비스를 ver1이 돌고있는 중간에 함께 배포하고 ver1을 줄이는 방식2. 블루 그린 업데이트 ver1을 한번에 없애고 빠르게 ver2를 배포 3. 카나리 업데이트 ver2를 일부 사용자에게만 미리 배포하고 안정성이 확인 되면 ver2를 배포
참고
배포 방식 - 카나리/블루 그린/롤링 업데이트 배포 방식
배포 방식도 간단히 deployment/release로 표현되기도 하지만.. 사실 많은 전략이 있다. 보통 웹 서비스에서 많이 사용되는 방식을 소개하면.. 다음과 같다. 1) 롤링 업데이트 (rolling update), 또는 Ramped
knight76.tistory.com
쿠버네티스에서 이를 무중단 배포하기 위해서는
첫번째 방법
| rs를 두개 만들고 kubectl edit에서 nginx2 replicas = 3 / nginx1 replicas = 0으로 수정 |
두번째 방법: svc 파일 수정하기
| 1. rs nginx1 : label = nginx 2. rs nginx2 : label = nginx2 -> 일단 두 rs 모두 운용하고 3. nginx1 운영하던 svc 파일을 수정 -> selecter label = nginx2 |
쿠버네티스 서비스
pod는 일시적이다 업데이트가 일어나거나 rs가 수정되거나,, 하면 사라졌다가 생겼다가 함
또한 pod의 ip 또한 예측할 수 없어 pod들을 대표하는 하나의 ip가 필요하다
+ service는 pod에 종속적이지 않고, service에 속하는 pod가 없어도 서비스는 동작 할 수 있다

서비스 생성하기
1. CLI
kubectl expose rs rs-name --name svc-name --port <port>이때 클러스터 ip 만들어짐 - 클러스터 내에서만 접근가능

클러스터 접근 확인해보기
# shell용 pod 만들기
kubectl run -it --rm centosshell --image=centos /bin/bash
curl 10.24.3.227
curl nginx-svc # 이름으로도 통신 가능함
그냥 pod는 ip로만 접근이 되지만 service는 ip, name으로 모두 접속 된다

클러스터 안에서 서비스 이름으로 통신이 가능한 이유는 kubeetes안에는 내부 dns 시스템이 갖추어있기 때문이다

여러개의 컨테이너를 가진 pod를 포함한 rs 및 service 만들기

컨테이너가 여러개이기 때문에 service 에서 port 를 여러개 줘야 한다!
배열형태이기 때문에 name 을 꼭 줘야한다

실행 후 같은 클러스터에 있는 shell에서 접속 확인을 해본다


같은 클러스터지만 네임스페이스가 다른 서비스에 접근하기 위해서는 FQDN 형식으로 통신해야 한다
kubectl create ns dev
kubectl run -it --rm centosshell -n dev --image=centos bash
curl nginx-tomcat.defaultFQDN 형식이란
같은 네임스페이스에서는 svc의 이름만 가지고도 통신이 가능했지만 다른 네임스페이스의 서비스에 접근하는 것이기 때문에 뒤에 네임스페이스까지 적어주는것을 의미한다
전부다 적으면 svcname.ns.svc.cluster.local 이지만 .svc.cluster.local은 생략할 수 있다

엔드포인트
엔드포인트는 서비스에서 아주 중요한 개념이다!
서비스는 pod와 연결되어 이 pod에 접근할 수 있는 하나의 ip를 제공하는데 이때 pod와 연결되는 방법에 엔드포인트가 사용된다
엔드포인트는 서비스와 pod를 연결하는 방법이다. 서비스는 파드에 직접 연결되지 않고 엔드포인트를 통해서 연결이 된다
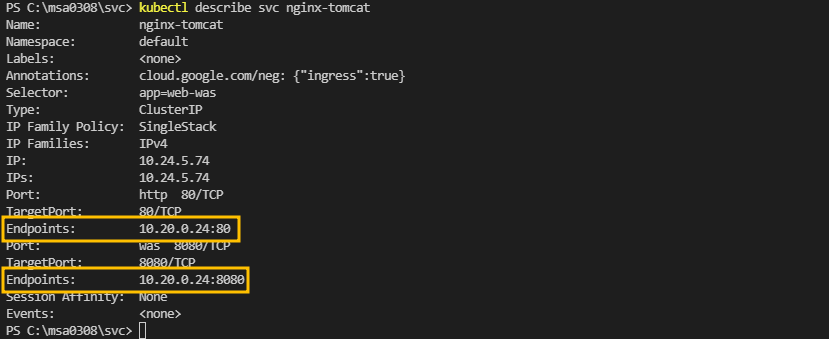
이는 서비스를 만들때 seletor를 만들면 자동으로 endpoint가 생성된다

svc 생성 yml 파일에 selector를 지정하면 엔드포인트는 자동으로 생성되며 이를 지정하지 않는경우 수동으로 엔드포인트를 잡아줄 수도 있다
엔드포인트를 수동으로 만드는 방법
클러스터 외부의 웹서버를 엔드포인트에 붙여보자
일단 서비스를 만들때 selector없이 만들고, end point yaml파일을 생성한다


이때 서비스에 접속해보면

같은 내용이 보임
svc를 통해서 외부의 오브젝트를 가져올 필요가 있나요? (수동으로 엔드포인트를 연결할 필요가 있나요?)
-> ex. S3 버킷 같은것 // 엔드포인트 = 연결통로 // DB는 on-prem 환경에 있을 가능성이 높다 (보안때문에)
-> EKS에서 만든 서비스에서 GKE에서 만든 DB를 사용해야 한다면? (DB는 보통 on-prem에 있다)
-> 사용하고자 하는 자원이 클러스터 내에 없는경우
svc와loadbalancer 등은 리소스와 연결해서 사용하는데 이때 연결하는 대상이 클러스터 내부에 있지 않아도 된다
svc의 엔드포인트는
1. 서비스를 만들때 selector에 의해 자동으로 만들어지던지
2. selector가 없을때는 수동으로 endpoint.yml를 통해 만들 수 있다
- 이때는 연결할 수 있는 오브젝트(pod, server, svc ... 통신이 가능한 것들)가 클러스터 안에 있어도, 밖에 있어도 된다
SVC에는 꼭 엔드포인트가 있어야 오브젝트가 연결될 수 있다
로드발란서와도 비슷한 개념임
오늘의 회고
- 오늘은 머리가 터져버리는줄 알았다,,!