
갬미의 성장일기
텐서플로우 개발자 자격증 준비하기 [2] - Intro (Course 1) 본문
Coarse1에서는 기본적인 개요에 대해 학습합니다
4주차 assignment 발췌
import tensorflow as tf
# GRADED FUNCTION: train_happy_sad_model
def train_happy_sad_model():
DESIRED_ACCURACY = 0.999
## 한 epoch가 끝날때 마다 'accuracy' 값을 확인하고 DESIRED_ACCURACY 이상일때 학습 종료
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if (logs.get('accuracy') > DESIRED_ACCURACY):
print("\nReached 99.9% accuracy so cancelling training!")
self.model.stop_training = True
callbacks = myCallback()
# This Code Block should Define and Compile the Model. Please assume the images are 150 X 150 in your implementation.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid') ## 이진분류 - sigmoid / 다준분류 - softmax 사용(확률값 사용하기 때문)
])
## optimizer 지정 // 따로 안해주고 optimizer='rmsprop' 해서 디폴트값 사용해도 됨
## loss도 데이터에 맞게 지정
from tensorflow.keras.optimizers import RMSprop
model.compile(loss='binary_crossentropy', optimizer=RMSprop(lr=0.001), metrics=['accuracy'])
model.summary()
# This code block should create an instance of an ImageDataGenerator called train_datagen
# And a train_generator by calling train_datagen.flow_from_directory
# ImageDataGenerator 사용시 SciPy 설치 필요 # pip install scipy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1 / 255)
# Please use a target_size of 150 X 150.
## class_mode - 디폴트값 다중클래스 // 데이터에 맞게 지정
train_generator = train_datagen.flow_from_directory(
"data/C1W4_image/",
target_size=(150, 150),
batch_size=10,
class_mode='binary'
)
## steps_per_epoch = 훈련 샘플 수 / 배치 사이즈
## 헷갈릴때는 steps_per_epoch = len(train_generator)//batch_size
history = model.fit(train_generator, steps_per_epoch=8, epochs=15, verbose=1,callbacks=[callbacks])
return history.history['accuracy'][-1]
train_happy_sad_model()tf.keras.models.Sequential
- layer의 순서를 정의
ImageDataGenerator - flow_from_directory
- model input으로 사용될 data를 전처리하는 API
ImageDataGenerator
- 정규화(1./255.)하는 이유 -> 원래 이미지는 0~255값을 가지지만 이를 0~1사이 값이나 다른 방식으로 정규화 하여 신경망 처리를 쉽게하기 위해 (raw pixel 값을 그대로 사용하는 경우는 거의 없다고 한다)
- 이미지 데이터 증강(Augmentation)을 위한 API
- 사용가능한 args 및 디폴트값 확인 (더보기 클릭)
tf.keras.preprocessing.image.ImageDataGenerator(
featurewise_center=False, samplewise_center=False,
featurewise_std_normalization=False, samplewise_std_normalization=False,
zca_whitening=False, zca_epsilon=1e-06, rotation_range=0, width_shift_range=0.0,
height_shift_range=0.0, brightness_range=None, shear_range=0.0, zoom_range=0.0,
channel_shift_range=0.0, fill_mode='nearest', cval=0.0,
horizontal_flip=False, vertical_flip=False, rescale=None,
preprocessing_function=None, data_format=None, validation_split=0.0, dtype=None
)https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator
tf.keras.preprocessing.image.ImageDataGenerator
Generate batches of tensor image data with real-time data augmentation.
www.tensorflow.org
.flow_from_directory(Directory):
- ImageDataGenerator를 적용할 이미지 경로를 지정해주는 것
- 이를 통해 numpy array iterator 객체를 만들어주며 fit 단계에서 batch size를 지정하지 않고 미리 batch size만큼 데이터를 전달하므로서 메모리 절약이 가능
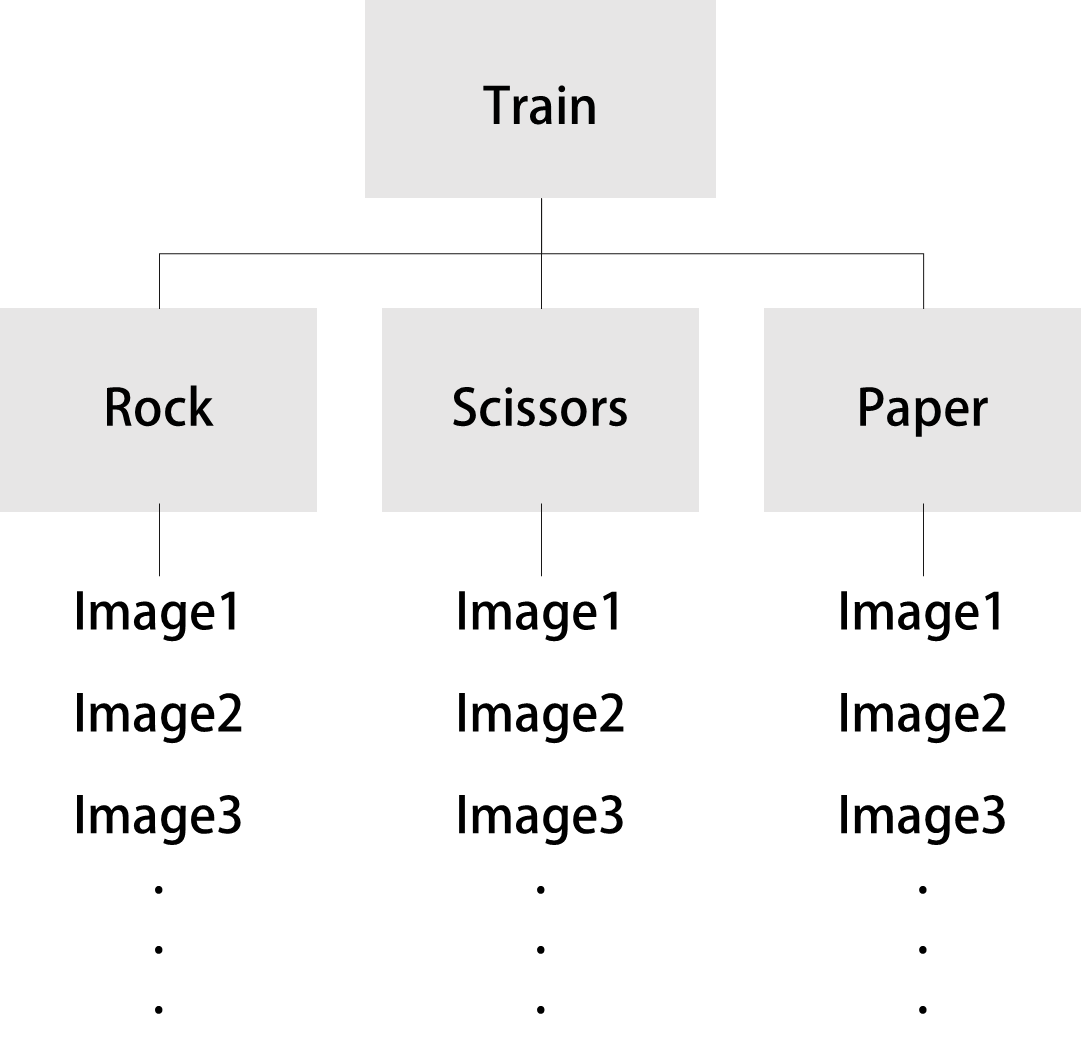
- Directory 하위에 class 별로 폴더가 있고 그 안에 이미지가 있으면 label을 따로 정해주지 않아도 알아서 지정해줌
- 사용가능한 args 및 디폴트값 확인 (더보기 클릭)
flow_from_dataframe(
dataframe, directory=None, x_col='filename', y_col='class',
weight_col=None, target_size=(256, 256), color_mode='rgb',
classes=None, class_mode='categorical', batch_size=32, shuffle=True,
seed=None, save_to_dir=None, save_prefix='',
save_format='png', subset=None, interpolation='nearest',
validate_filenames=True, **kwargs
)- class_mode = 'categorical' : 다중분류
class_mode = binary'' : 이진분류
** 참고
.flow(data, labels) 도 가능
- 폴더별로 나눠지지 않은 경우에 사용
- 사용가능한 args 및 디폴트값 확인 (더보기 클릭)
flow(
x, y=None, batch_size=32, shuffle=True, sample_weight=None, seed=None,
save_to_dir=None, save_prefix='', save_format='png',
subset=None
)
'Deep Learning > Tensorflow cert' 카테고리의 다른 글
| 텐서플로우 개발자 자격증 준비하기 [3] - CV (Course 2) (0) | 2021.11.29 |
|---|---|
| 텐서플로우 개발자 자격증 준비하기 [1] - 응시 환경 설정 및 후기 (0) | 2021.11.28 |
